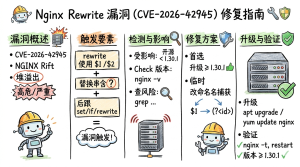
Nginx rewrite 模块漏洞 (CVE-2026-42945) 修复指南
- 漏洞概述
CVE-2026-42945(代号 NGINX Rift)是 nginx ngx_http_rewrite_module 模块中的一个堆缓冲区溢出漏洞,已存在约18年(自2008年起),影响 nginx 0.6.27 至 1.30.0 版本。
潜在影响 服务中断:攻击者可使 nginx worker 进程崩溃,导致服务重启或拒绝服务
远程代码执行:在关闭 ASLR 的系统中,攻击者可能执行任意代码
- 漏洞触发条件 此漏洞不是任何 nginx 安装都会触发,而是依赖特定的配置模式。必须同时满足以下三个条件
# ❌ 漏洞配置:同时满足三个条件
location / {
rewrite ^/(.*)$ /index.php?path=$1 last; # 未命名捕获 + 问号
set $var $uri; # 后跟 set 指令
}
# ✅ 安全配置:使用命名捕获
location / {
rewrite ^/(?
<path>.*)$ /index.php?path=$path last;
set $var $uri;
}- 漏洞检测
3.1 检查 nginx 版本
nginx -v 2>&1 # 如果版本在 0.6.27 ~ 1.30.0 之间,则版本存在漏洞隐患
手动检查配置文件
# 检查所有 rewrite 规则
grep -RnE 'rewrite.*\$[0-9].*\?' /etc/nginx/
# 检查 rewrite 后是否紧跟 set/if/rewrite
grep -A1 -E 'rewrite.*\$[0-9].*\?' /etc/nginx/ | grep -E '(rewrite|set|if)'使用自动化扫描工具 nginx-lint(官方推荐) CVE-2026-42945-scanner(开源工具) https://git.sr.ht/~hrbrmstr/cve-2026-42945-scanner
修复方案 方案一:升级 nginx(首选) nginx 官方 1.30.1+ 或 1.31.0+ 从 [nginx.org] 下载
方案二:临时缓解(无法立即升级时) 将未命名捕获改为命名捕获,这是官方认可的临时修复方案
原写法(漏洞风险) ([a-zA-Z]+) 改成 (?
<name>[a-zA-Z]+)
?
<name> 就是(命名捕获)实际修复示例 示例1:PHP 前端控制器
# 修复前(漏洞)
location / {
rewrite ^/(.*)$ /index.php?route=$1 last;
set $page $uri;
}
#修复后(安全)
location / {
rewrite ^/(?
<route>.*)$ /index.php?route=$route last;
set $page $uri;
}
#修复前
rewrite ^/user/([0-9]+)/profile/(.*)$ /profile.php?id=$1&tab=$2 last;
# 修复后
rewrite ^/user/(?
<id>[0-9]+)/profile/(?<tab>.*)$ /profile.php?id=$id&tab=$tab last;
# 修复前
location ~ ^/category-([a-zA-Z]+)-([0-9]+)\.html {
set $cat_name $1;
set $page $2;
try_files /category/${cat_name}/list_${page}.html /app/list.php?cat=$1&page=$2;
}
# 修复后
location ~ ^/category-(?
<cat_name>[a-zA-Z]+)-(?<page>[0-9]+)\.html {
set $cat_name $cat_name;
set $page $page;
try_files /category/${cat_name}/list_${page}.html /app/list.php?cat=${cat_name}&page=${page};
} 方案三:移除问号(特定场景适用) 如果 rewrite 目标不需要传递参数,可移除
# 修复前
rewrite ^/oldpath/(.*)$ /newpath/$1? last;
# 修复后(移除 ?)
rewrite ^/oldpath/(.*)$ /newpath/$1 last;参考
https://nginx.org/en/security_advisories.html
https://depthfirst.com/research/nginx-rift-achieving-nginx-rce-via-an-18-year-old-vulnerability









近期评论